연산자
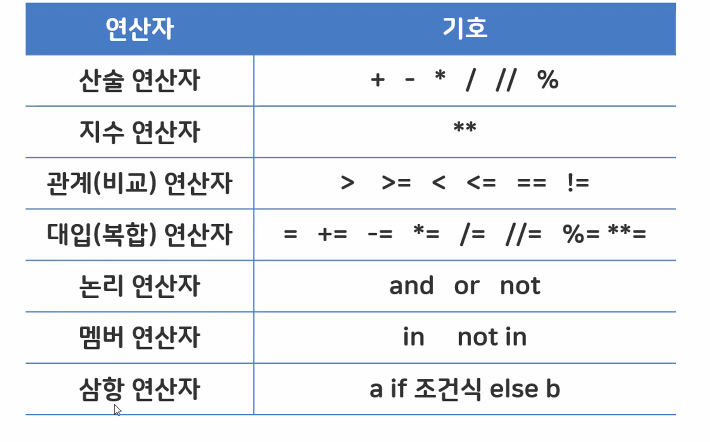
그외.
& - bitwise 연산
리스트
- 순서가 있는 수정 가능한 객체의 집합
- 대괄호로 작성되어지며 리스트 내부의 값은 쉼표 (, )로 구분
- 하나의 리스트에 다양한 자료형 포함 가능
슬라이싱 가능
a = [0,1,2,3,4,5]
a[0:2] ## [0,1] 반환
a[:2] ## 0 은 생략 가능
a[:-2] ## [0,1,2,3] 반환 (-2 인덱스는 뒤에서 두번째.)
각종 리스트 함수
a = [1,0,5,4]
a.sort() ## a 리스트 오름차순 정렬
## sort 의 매개변수 reverse 를 통해 정렬 순서 변경 가능)
a.sort(reverse = True) ## a 리스트 내림차순 정렬
### sorted 로 새로운 리스트 반환 가능
b = sorted(a)
a.reverse() a 역순으로.
a.append(5) a 제일 끝에 값 추가.
c = a.pop() a 제일 끝 값 제거 후 반환
a.extend([7,8,9]) a 끝에 리스트 값들을 추가
a.insert(x,y) 인덱스 x 에 값 y 를 추가. 뒤 값들은 뒤로 밀림. % O(n)
a.remove(x) 첫번째로 찾는 x 값 제거. 뒤 값들은 한칸씩 앞으로 땡겨짐 O(n)
## 없는 값을 삭제하려고 하면 에러 발생
## ValueError: list.remove(x): x not in list
Dictionary
다른 언어의 Map 같은 느낌
- key 와 value 값으로 이루어져 있음. key - value 쌍
- 순서가 없음
- ==로 키, 밸류가 같은 딕셔너리인지 비교 가능 (참조값이 아닌 키, 밸류 값 비교)
- 같은 딕셔너리인지 (같은 참조) 비교하려면 is 사용
# 값가져오기1
dic['addr']
# 값 가져오기2
dic.get['addr']
###### 차이점
print(my_info_dict['name']) ## 에러
print(my_info_dict.get('aaaa')) ## none 반환 <class 'NoneType'>
## 키 값 가져오기.
dic.keys()
## value 값 가져오기
dic.values()
## 둘다 가져오기 // 각각의 (key, value) 튜플로 만들어진 리스트.
dic.items()
## 튜플로 받은 것들은 for loop 을 사용해서 간단하게 받을수 있음.
for key,value in dic.items()
print(key,value)
## 키 값이 딕셔너리에 존재하는지 안하는지 True/False 반환.
'name' in dic
# del 딕셔너리[키]
del dic('name')
## 모든 값 삭제
dic.clear()
defaultdict
- dictionary 에 값을 저장할때 기존에 키가 있는지 없는지 항상 확인 후 넣어야 하는 번거로움을 해결해주는 라이브러리
- from collections import defaultdict
Set
- 중복허용 x
- 순서 없음
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
#### 교집합
s1 & s2
s1.intersection(s2)
## 합집합
s1 | s2
s1.union(s2)
## 차집합
s1 - s2
s1.difference(s2)
s2 - s1
s2.difference(s1)
### add. 값 추가
s1.add(4)
### update 여러 값 한번에 추가
s1.update(4,5,6)
## 특정 값 제거
s1.remove(4)제어문
- 파이썬은 들여쓰기로 코드를 구분함.
- 제어문 안에 아무 코드도 없으면 에러. (pass 로 일단 넘길수 있음.)
3항 연산자
# [a] if [조건식] else [b]
# True 일때는 a Flase 일때는 b
score = 60
print("합격") if score >= 60 else print("불합격")
if
괄호 대신 콜론 : 과 들여쓰기 사용
if 조건 :
실행코드
elif 조건 :
실행코드
else :
실행코드
FOR
## 문법
for 변수 in 리스트(또는 튜플, 문자열):
수행할_문장1
수행할_문장2
...
## range 사용.
## range(시작숫자 이상, 종료숫자 미만, 증가량)
## 감소 --- range(10,1,-1) 10~~~2까지
## 시작숫자가 0이면 생략가능. 증가숫자가 1이면 생략가능
for i in range(1,10,1):
print(i)
## 리스트의 길이로 range -> i 는 인덱스로 사용가능.
for i in range(len(food_list)) :
print(food_list[i])
반복문 안에서
continue
를 만날 시 더이상 코드를 진행하지 않고 다음 반복으로 넘어감.
break
을 만날 시 반복문 종료
반복문 사용시 유용한 기능들
li = [[1,2], [3,4],[5,6]]
# 구조분해할당. 각 값들이 튜플이나 리스트일 경우 분해할당으로 바로 사용할수 있음.
for a,b in li :
print(a,b)
# enumerate을 사용해서 인덱스 값을 함께 받기
for i, items in enumerate(li) :
print(i, items)
# zip 을 사용해서 같은 길이의 리스트 값들을 함께 받을 수 있도록.
li2 = [10, 40,60]
for item1, item2 in zip(li, li2) :
###
## zip, enumerate, 구조분해할당 전부 사용하면 편함.
WHILE
while 조건:
수행할_문장1
수행할_문장2
수행할_문장3
...
## 무한루프
while True :
...python 에는 do while 문법이 없음.
비슷하게는 만들수 있지만..